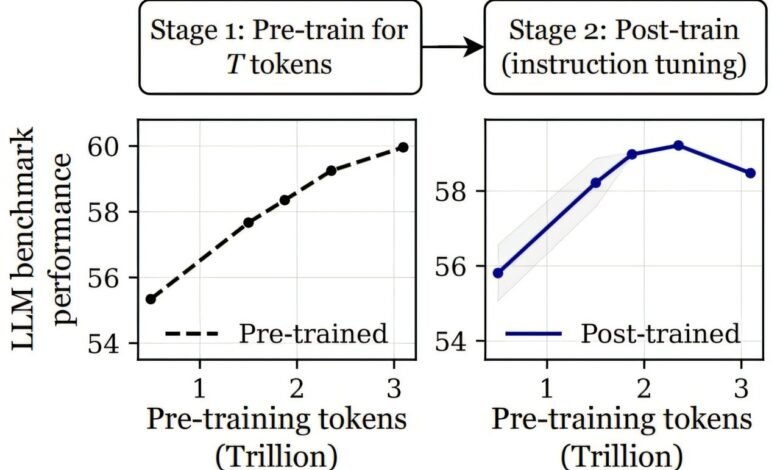
Los modelos lingüísticos con un pretruento extenso pueden exhibir sobreentrenamiento catastrófico, donde el rendimiento de los modelos posttrados se degrada a medida que se extiende la etapa previa al entrenamiento. Crédito: ARXIV (2025). Doi: 10.48550/arxiv.2503.19206
Un pequeño equipo de investigadores de IA de la Universidad Carnegie Mellon, la Universidad de Stanford, la Universidad de Harvard y la Universidad de Princeton, todos en los EE. UU., Descubrieron que si los modelos de idiomas grandes están sobresalidos, podría dificultar la atención. En su artículo publicado en el servidor de preimpresión ARXIV, el grupo comparó el impacto de diferentes cantidades de capacitación en un solo LLM.
En los últimos años, mientras los investigadores de IA buscan mejorar sus productos para hacerlos más “inteligentes”, muchos han sido impulsados por el mantra de que cuanto más capacitación se da un modelo, mejor será el modelo al final. En este nuevo estudio, el equipo de investigación ha encontrado alguna evidencia que sugiere que puede haber un punto de disminución de los retornos con la capacitación del modelo de idioma.
Los investigadores llegaron a esta conclusión mientras probaban el retorno al entrenar dos versiones diferentes del LLM OLMO-1B. En un escenario, lo entrenaron usando 2.3 billones de tokens, mientras que en el otro usaron 3 billones de tokens. Luego compararon los escenarios probándolos con varios puntos de referencia, como ARC y Alpacaeval. Al hacerlo, descubrieron que el modelo entrenado con más tokens en realidad fue peor cuando se probó, hasta un 3% peor.





Sorprendidos por sus hallazgos, realizaron más pruebas y encontraron resultados similares, lo que sugiere que hay algún punto en el que más entrenamiento comienza a hacer que los modelos sean menos “inteligentes”. El equipo de investigación lo llama “sobreentrenamiento catastrófico” y sugiere que se debe a lo que describen como “sensibilidad progresiva”.
Sugieren además que a medida que aumenta el número de fichas, cuanto más frágil se vuelve un modelo, lo que significa que el ajuste fino, que puede verse como agregando ruido, comienza a revertir las ganancias en mejoras que se vieron antes del punto de estrés.
Esquema para ilustrar cómo la escala de la tasa de aprendizaje óptima puede afectar las evaluaciones del modelo en función de los tokens de pre-entrenamiento T. Crédito: ARXIV (2025). Doi: 10.48550/arxiv.2503.19206
Para probar su teoría, agregaron ruido gaussiano a algunos de los modelos y descubrieron que hacerlo condujo al mismo tipo de degradación del rendimiento que habían presenciado antes. Han nombrado el punto de no retorno, el “punto de inflexión”. Después de ese punto, sugieren, cualquier entrenamiento adicional reducirá la estabilidad del modelo, lo que hace que sea más difícil sintonizar una manera útil para un conjunto deseado de aplicaciones.
Los investigadores concluyen sugiriendo que avanzar, los desarrolladores de los modelos LLM pueden tener que hacer estimaciones sobre cuánto capacitación es suficiente, o encontrar otros tipos de métodos que permitan capacitación adicional con un punto de inflexión más distante.
Más información: Jacob Mitchell Springer et al, los modelos de lenguaje sobretrabonado son más difíciles de ajustar, ARXIV (2025). Doi: 10.48550/arxiv.2503.19206
Información en el diario: ARXIV
© 2025 Science X Network
Cita: los modelos de lenguaje grande en exceso pueden hacer que sean más difíciles de inyectar (2025, 14 de abril) recuperado el 14 de abril de 2025 de https://techxplore.com/news/2025-04-large-language-harder-fine-tune.html
Este documento está sujeto a derechos de autor. Además de cualquier trato justo con el propósito de estudio o investigación privada, no se puede reproducir ninguna parte sin el permiso por escrito. El contenido se proporciona solo para fines de información.





