El nuevo modelo puede generar pistas de audio y música a partir de diversas entradas de datos
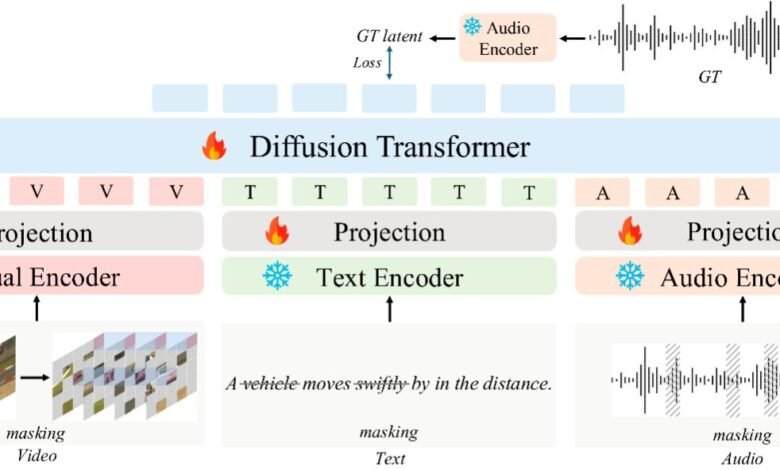
Arquitectura del audio. Esta figura representa la arquitectura subyacente del audiox, destacando su marco de transformadores de difusión con la nueva estrategia de enmascaramiento multimodal que permite el aprendizaje de representación unificada a través de modalidades de texto, videos y audio. Crédito: Tian et al.
En los últimos años, los científicos informáticos han creado varias herramientas de aprendizaje automático de alto rendimiento para generar textos, imágenes, videos, canciones y otro contenido. La mayoría de estos modelos computacionales están diseñados para crear contenido basado en instrucciones basadas en texto proporcionadas por los usuarios.
Los investigadores de la Universidad de Ciencia y Tecnología de Hong Kong introdujeron recientemente Audiox, un modelo que puede generar pistas de audio y música de alta calidad utilizando textos, imágenes de video, imágenes, grabaciones de música y audio como entradas. Su modelo, introducido en un artículo publicado en el servidor de preimpresión ARXIV, se basa en un transformador de difusión, un algoritmo avanzado de aprendizaje automático que aprovecha la llamada arquitectura del transformador para generar contenido al no-colar los datos de entrada que recibe.
“Nuestra investigación proviene de una pregunta fundamental en la inteligencia artificial: ¿cómo pueden los sistemas inteligentes lograr una comprensión y generación intermodal unificadas?” Wei Xue, el autor correspondiente del documento, dijo a Tech Xplore. “La creación humana es un proceso perfectamente integrado, donde la información de diferentes canales sensoriales está naturalmente fusionado por el cerebro. Los sistemas tradicionales a menudo se han basado en modelos especializados, no capturar y fusionar estas conexiones intrínsecas entre las modalidades”.




El objetivo principal del reciente estudio dirigido por Wei Xue, Yike Guo y sus colegas era desarrollar un marco de aprendizaje de representación unificado. Este marco permitiría que un modelo individual procese información en diferentes modalidades (es decir, textos, imágenes, videos y pistas de audio), en lugar de combinar modelos distintos que solo pueden procesar un tipo específico de datos.
Crédito: Zeyue Tian et al
“Nuestro objetivo es permitir que los sistemas de IA formen redes conceptuales intermodales similares al cerebro humano”, dijo Xue. “El audiox, el modelo que creamos, representa un cambio de paradigma, dirigido a abordar el doble desafío de la alineación conceptual y temporal. En otras palabras, está diseñado para abordar tanto ‘qué’ (alineación conceptual) como ‘cuando’ (alineación temporal) las preguntas simultáneamente.
El nuevo modelo basado en transformadores de difusión desarrollado por los investigadores puede generar pistas de audio o música de alta calidad utilizando cualquier datos de entrada como guía. Esta capacidad de convertir “cualquier cosa” en audio abre nuevas posibilidades para la industria del entretenimiento y las profesiones creativas. Por ejemplo, permitir a los usuarios crear música que se ajuste a una escena visual específica o usar una combinación de entradas (por ejemplo, textos y videos) para guiar la generación de pistas deseadas.
“El audio se basa en una arquitectura del transformador de difusión, pero lo que lo distingue es la estrategia de enmascaramiento multimodal”, explicó Xue. “Esta estrategia reinventa fundamentalmente cómo las máquinas aprenden a comprender las relaciones entre los diferentes tipos de información.
“Al oscurecer los elementos en las modalidades de entrada durante el entrenamiento (es decir, eliminar selectivamente parches de marcos de video, tokens de texto o segmentos de audio), y capacitar al modelo para recuperar la información faltante de otras modalidades, creamos un espacio de representación unificado”.
Descripción general de las capacidades del audio. Este diagrama ilustra las capacidades versátiles de Audiox en múltiples tareas, incluidos texto a audio, video a audio, interpago de audio, texto a música, video a musica y finalización de la música. El modelo demuestra un fuerte rendimiento en la generación de audio contextualmente apropiado para entradas diversas. Crédito: Tian et al.
El audio es uno de los primeros modelos en combinar descripciones lingüísticas, escenas visuales y patrones de audio, capturando el significado semántico y la estructura rítmica de estos datos multimodales. Su diseño único le permite establecer asociaciones entre diferentes tipos de datos, de manera similar a la forma en que el cerebro humano integra información recogida por diferentes sentidos (es decir, visión, audición, gusto, olor y tacto).
“El audio es, con mucho, el modelo de la Fundación de Audio más completo, con varias ventajas clave”, dijo Xue. “En primer lugar, es un marco unificado que admite tareas altamente diversificadas dentro de una arquitectura de modelo único. También permite la integración intermodal a través de nuestra estrategia de capacitación enmascarada multimodal, creando un espacio de representación unificado. Tiene capacidades de generación versátiles, ya que puede manejar tanto el audio general como la música con alta calidad, entrenada en datos de alta calidad, incluidos nuestros recopilos recién curados”. “.
En las pruebas iniciales, se descubrió que el nuevo modelo creado por Xue y sus colegas producía pistas de audio y música de alta calidad, integrando con éxito textos, videos, imágenes y audio. Su característica más notable es que no combina diferentes modelos, sino que utiliza un solo transformador de difusión para procesar e integrar diferentes tipos de entradas.
“El audio admite diversas tareas en una arquitectura, que van desde texto/video hasta audio hasta la ingenio de audio y la finalización de la música, avanzando más allá de los sistemas que generalmente se destacan solo en tareas específicas”, dijo Xue. “El modelo podría tener varias aplicaciones potenciales, que abarcan la producción de películas, la creación de contenido y los juegos”.
Comparación cualitativa en varias tareas. Crédito: ARXIV (2025). Doi: 10.48550/arxiv.2503.10522
El audio pronto podría mejorarse aún más e implementarse en una amplia gama de configuraciones. Por ejemplo, podría ayudar a los profesionales creativos en la producción de películas, animaciones y contenido para las redes sociales.
“Imagine que un cineasta ya no necesita un artista de Foley para cada escena”, explicó Xue. “El audio podría generar automáticamente pasos en la nieve, puertas crujientes o hojas de susurro basadas únicamente en el metraje visual. De manera similar, los influencers podrían usar instantáneamente la música de fondo perfecta a sus videos de baile tiktok o por youtubers para mejorar sus vlogs de viajes con paisajes sonoros locales auténticos, todos los generados a punto de hacer”.
En el futuro, los desarrolladores de videojuegos también podrían utilizar el audiox para crear juegos inmersivos y adaptativos, en los que los suena de fondo se adaptan dinámicamente a las acciones de los jugadores. Por ejemplo, a medida que un personaje se mueve de un piso de concreto a la hierba, el sonido de sus pasos podría cambiar, o la banda sonora del juego podría volverse más tensa a medida que se acercan a una amenaza o enemigo.
“Nuestros próximos pasos planificados incluyen extender el audio a la generación de audio de forma larga”, agregó Xue. “Además, en lugar de simplemente aprender las asociaciones de los datos multimodales, esperamos integrar la comprensión estética humana dentro de un marco de aprendizaje de refuerzo para alinearse mejor con las preferencias subjetivas”.
Más información: Zeyue Tian et al, Audiox: Transformador de difusión para la generación de cualquier cosa a audio, ARXIV (2025). Doi: 10.48550/arxiv.2503.10522
Información en el diario: ARXIV
© 2025 Science X Network
Cita: El nuevo modelo puede generar pistas de audio y música de diversas entradas de datos (2025, 14 de abril) recuperado el 14 de abril de 2025 de https://techxplore.com/news/2025-04-generate-audio-music-tracks-diverse.html
Este documento está sujeto a derechos de autor. Además de cualquier trato justo con el propósito de estudio o investigación privada, no se puede reproducir ninguna parte sin el permiso por escrito. El contenido se proporciona solo para fines de información.





